데이터베이스 (Database)
- 구조화된 정보나 데이터 집합
- 데이터는 테이블 형태로 조직화 되며, 각 테이블은 여러 개의 열과 행으로 구성
- 목적 : 데이터를 필요할 때 쉽게 검색하고 효율적으로 관리
DBMS (DataBase Management System)
DB 를 관리하고 운영하는 SW
ex) MySQL, Oracle, PostgreSQL 등
CAP 이론
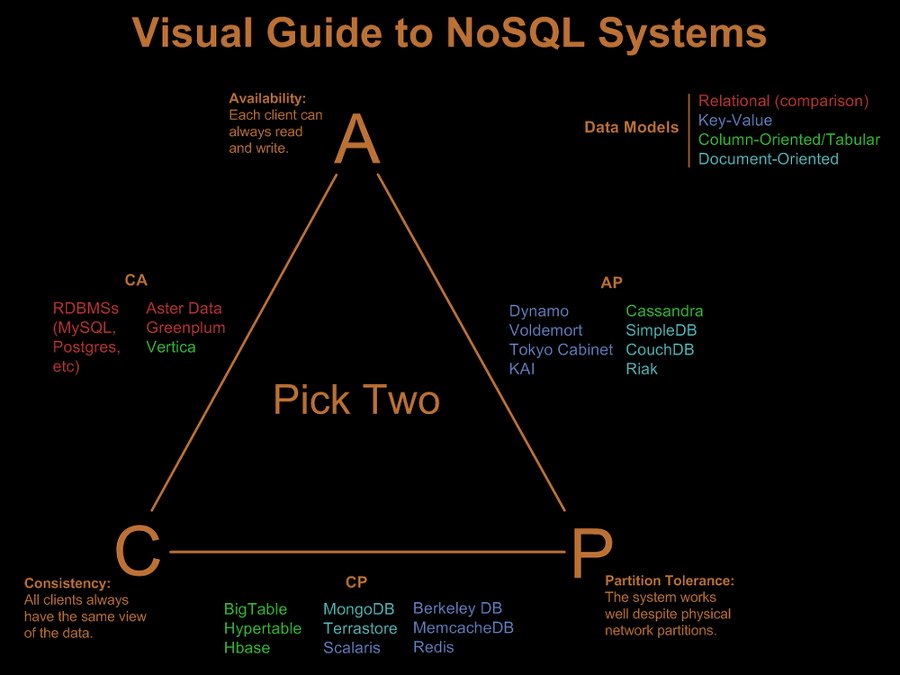
DB에서 일관성(Consistency), 가용성(Availability), 분할 허용성(Partition Tolerance)의 세 가지 속성 중 두 가지 속성만 만족시킬 수 있는 원칙.
일반적으로 RDBMS는 CA 만족하며, NoSQL은 CP, AP 형태
Consistency (일관성)
- 사용자가 동시에 같은 데이터를 봄
ex) 어떤 사용자가 데이터를 업데이트하면, 다른 사용자들은 해당 업데이트 된 값을 바로 볼 수 있어야 함
Availability (가용성)
- 모든 요청에 대해 오류 없는 응답을 보장
Partition Tolerance (분할 허용성)
- 네트워크 연결이 끊기더라도 정상적으로 동작해야함
파티셔닝 (Partitioning)
테이블이나 인덱스를 관리하기 쉽고 더 빠르게 접근할 수 있도록 작은 단위로 나누는 기술
샤딩과 달리 주로 단일 DB 내에서 데이터를 조직화하는 데 사용
- 장점 : DML 작업이 분산되어 성능 향상
- 단점 : JOIN 성능 저하
샤딩 (Sharding)
수평 파티셔닝 방식으로, 테이블을 row 단위(Shards) 로 나눠서 여러 서버에 분산시키는 기술
- 장점 : 데이터와 트래픽을 여러 서버에 분산시켜, 단일 DB 서버에 대한 부하를 줄이고 쿼리 응답 시간 단축
Clustering과 Replication
Clustering
- 여러 서버가 함께 작동하여 단일 DB처럼 동작하게 하는 기술
- 서버는 DB 전체 또는 일부를 공유하여 부하 분산, 고가용성 등의 목적으로 구성
Replication
- 데이터를 하나 이상의 DB에 복사하여 데이터 사본을 유지하는 기술
- 데이터 백업, 분산 처리 등을 목적
- 장점 : 데이터 복구 가능. 사용자는 가장 가까운 서버에서 데이터를 읽을 수 있어 읽기 속도 향상
SQL (Structured Query Language)
관계형 DB에서 사용되는 언어
종류
- DDL (Data Definition Language) : DB를 정의하는 언어로 테이블 생성/수정/삭제 등의 역할 ( alter, create, drop )
- DML (Data Manipulation Language) : DB 안의 검색, 삽입, 갱신, 삭제를 위한 언어 ( select, insert, update, delete )
- DCL (Data Control Language) : DB에 접근하거나 권한 부여하는 등의 역할 ( commit, rollback, grant, revoke )
SQL 수행 순서
FROM, ON, JOIN > WHERE, GROUP BY, HAVING > SELECT > DISTINCT > ORDER BY > LIMIT / OFFSET
- FROM : 테이블 JOIN 전에 각 테이블을 먼저 읽음
- ON : JOIN 조건 확인
- JOIN : FROM, ON 조건을 바탕으로 테이블 결합
- WHERE : 조건에 따라 행 필터링
- GROUP BY : 그룹화
- HAVING : GROUP BY를 통해 생성된 데이터에 대한 필터링
- SELECT : 결과로 보여질 컬럼이나 표현식 연산
- DISTINCT : 중복 제거
- ORDER BY : 정렬
- LIMIT / OFFSET
JOIN에서 ON과 WHRER
- ON : WHERE 보다 먼저 실행되어 JOIN 하기 전 필터링
- WHERE : JOIN 한 뒤에 필터링
RDBMS와 NoSQL

RDBMS
데이터를 2차원 테이블 형태로 표현.
SQL을 사용하여 데이터 저장, 질의, 수정 삭제 등을 할 수 있음
데이터 구조가 명확하고, 관계를 맺고 있는 데이터가 자주 변경되는 시스템인 경우 적합
- 장점 : 스키마에 맞춰 관리 되어 중복을 피하고 데이터의 정합성 보장
- 단점 : 시스템이 복잡해질 경우 쿼리 복잡해지고 Scale-out이 어려움(Scale-up만 가능)
NoSQL(Not Only SQL)
다양한 데이터 저장 방식 사용하여 관리되는 DB
정확한 데이터 구조를 알 수 없거나 변경/확장 될 수 있는 경우 적합
- 장점 : 스키마가 없어 변경에 유연하게 대처 가능. RDBMS에 비해 scale out이 쉬워 대용량 데이터 처리시 성능 이점
- 단점 : 데이터 중복 발생. 중복된 데이터가 변경될 경우 모든 컬렉션에서 수정해야 함
- 데이터 모델에 따라 분류
- Key-Value Data Model: 하나의 키에 하나의 데이터 저장 ex. Redis
- Document Data Model: Key-Value 모델을 개념적으로 확장해서 하나의 키에 하나의 구조화된 문서를 저장 ex. MongoDB
- Column-Family: Cassandra, HBase
- Graph Model
ORM (Object Relational Mapping)
SQL 언어가 아닌 개발 언어로 DB를 접근할 수 있는 툴
- 장점 : DBMS에 종속적이지 않으며 비즈니스 로직에 집중할 수 있음
- 단점 : 시스템 복잡성이 클 경우 구현 난이도 증가 및 속도 저하
데이터 무결성
데이터의 정확성, 일관성, 유효성이 유지되는 것
이를 통해 DB의 신뢰성을 보장할 수 있음
- 엔티티 무결성(Entity Integrity) : 모든 테이블은 primary key를 가져야 하며 이 키를 통해 각 행을 유일하게 식별할 수 있어야 하고 빈 값은 허용되지 않음
- 참조 무결성 (Referential Integrity) : Foreign Key는 다른 테이블의 기본 키를 참조하여, 테이블 간의 데이터 관계가 유효하고 일관되게 유지
ex) 주문 테이블의 '고객 ID' 필드가 고객 테이블의 'ID' 필드를 외래 키로 참조하면, 주문 테이블에 있는 모든 고객 ID는 고객 테이블에 존재해야 함 - 도메인 무결성 (Domain Integrity) : 각 컬럼에 설정된 데이터 타입/포맷/범위 등이 유지되어야 함
ex) 날짜 필드에는 올바른 날짜 형식만 저장되어야 하고, 성적 필드에는 0에서 100 사이의 값만 입력될 수 있음
Key
특정 데이터를 식별하거나 정렬할 때 사용되는 속성
- Candidate Key
- Primary Key로 사용할 수 있는 속성들(유일성, 최소성)
- Candidate key 중 Primary Key를 제외한 나머지는 모두 Alternate Key
- Primary Key
- 특정 행을 구별할 수 있는 속성(Attribute)
- 테이블 당 1개이며 중복된 값이나 null 값 허용 되지 않음
- Foreign Key
- 다른 테이블의 Unique Key(유일성 보장)를 참조하는 속성 (null값이 있을 수 있음)
- 두 테이블 간의 관계를 생성
Primary Key와 Unique Key
두 개의 Key 모두 유일성 보장되나 Unique Key는 모든 값 중 유일하게 하나에 대한 NULL을 허용
Transaction
DB 상태를 변화시키는 논리적인 작업 단위(일련의 연산)
수행 중에 한 작업이라도 실패하면 모두 실패하고(Rollback), 모두 성공해야 성공하는(Commit) 작업의 완전성을 보장
트랜잭션은 ACID의 네 가지 특성을 충족해야 함
- Atomicity(원자성) : 모든 연산은 전부 성공이거나 전부 실패해야 함 (부분 실행 불가)
- Consistency(일관성): 트랜잭션 실행 전 후로 DB의 모든 규칙이 유지되어야 함
- Isolation(고립성): 트랜잭션은 다른 트랜잭션과 독립적으로 수행. 서로 영향이 없어야 함
- Durability(지속성): 시스템에 문제가 있더라도 완료된 트랜잭션의 결과 유지
Join
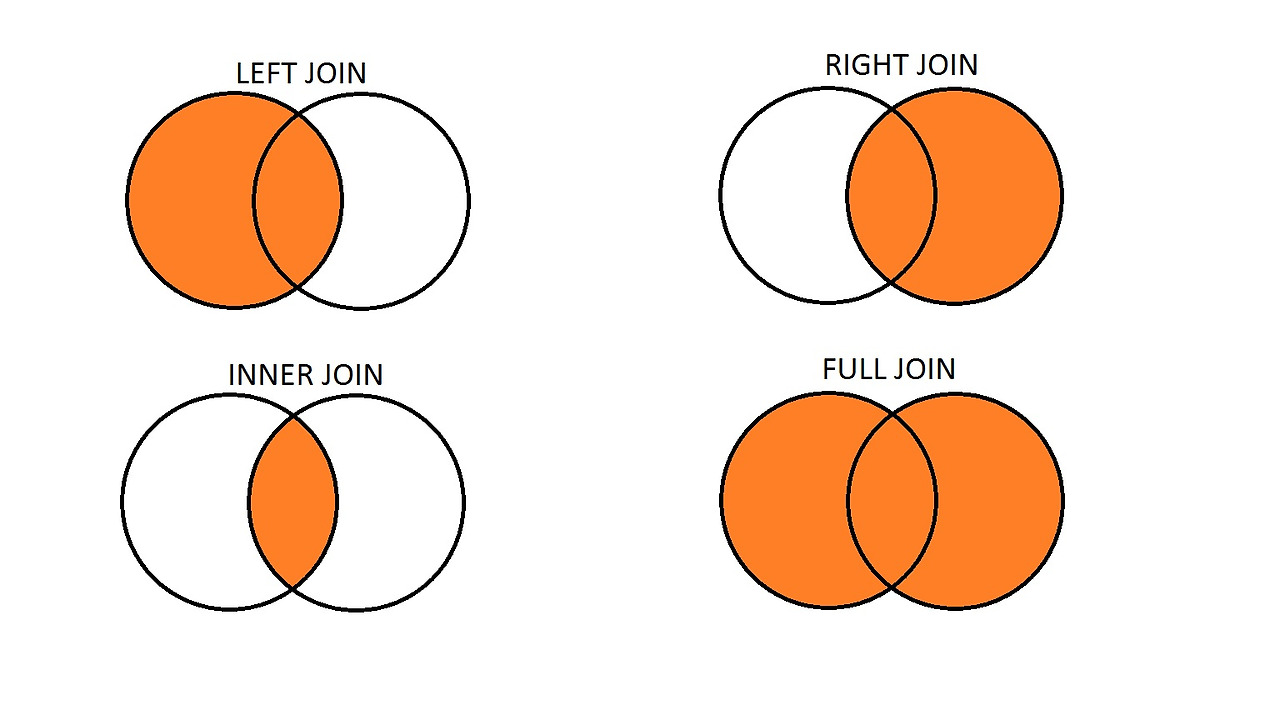
두 개 이상의 테이블을 결합하는 연산
- Inner Join : 교집합
- Left Join : 왼쪽 테이블의 모든 행, 오른쪽 테이블에서 일치하는 행
- Right Join : 왼쪽 테이블에서 일치하는 행, 오른쪽 테이블의 모든 행
- Outer Join : 합집합, 두 테이블의 모든 행을 반환하며, 일치하는 행이 없는 경우 NULL로 채워짐
UNION과 UNION ALL
여러개의 SQL문을 합쳐 하나의 SQL문을 만들어 줌
- UNION : 두 쿼리의 결과 중에서 중복되는 값을 삭제하여 나타냄
- UNION ALL : 두 쿼리의 결과 중에서 중복되는 값을 모두 보여줌. 중복체크를 하지 않기 때문에 속도가 더 빠름
DROP과 TRUNCATE와 DELETE
- DELETE : 데이터 삭제
- TRUNCATE : 전체 데이터를 한번에 삭제
- DROP : 테이블 자체를 삭제
Index
데이터 검색 속도를 향상시키기 위해 사용되는 자료 구조
- 장점 : 검색/정렬 성능 향상
- 단점 : 별도의 저장 공간 사용. 추가/삭제/수정의 경우 인덱스도 함께 갱신되어야 해서 성능 저하
사용하면 좋은 경우 : Where/Join/Foreign Key 에 자주 사용되는 열
피해야 하는 경우 : 데이터 중복이 많고(낮은 Cardinaity) DML이 자주 발생하는 열
DML 발생할 때
- INSERT: 기존 Block에 여유가 없을 때, 새로운 Data가 입력
- 새로운 Block을 할당 받은 후, Key를 옮기는 작업 수행
- Index split 작업 동안, 해당 Block의 Key 값에 대해서 DML이 블로킹 (대기 이벤트 발생)
- DELETE
- Table에서 data가 delete 되는 경우 : Data가 지워지고, 다른 Data가 그 공간을 사용 가능
- Index에서 Data가 delete 되는 경우 : Data가 지워지지 않고, 사용 안 됨 표시
- Table의 Data 수와 Index의 Data 수가 다를 수 있음
- UPDATE
- Table에서 update가 발생하면 → Index는 Update 할 수 없음
- Index에서는 Delete가 발생한 후, 새로운 작업의 Insert 작업 / 2배의 작업이 소요
작동 원리
일반적으로 B-Tree 인덱스 사용.
B-Tree 인덱스는 Key(column 값)와 포인터(Key에 해당하는 행의 위치를 가리키는 주소)의 조합으로 구성됨
DB Lock
여러 사용자가 DB를 사용할 때 발생할 수 있는 데이터 충돌을 방지하기 위해 사용.
Lock은 특정 데이터에 대한 접근을 제한하여, 한 번에 한 프로세스만이 데이터를 변경하거나 읽을 수 있도록 보장
- 공유락(Shared Lock) : 데이터를 읽을 때 사용. 동시에 같은 데이터를 읽을 수 있지만 변경은 불가
- 베타락(Exclusive Lock) : 데이터 변경할 때 사용. 특정 트랜잭션만 접근할 수 있음
※ DeadLock : 두 개 이상의 트랜잭션이 서로의 락 해제를 무한히 기다리는 상태.
옵티마이저 (Optimizer)
SQL 쿼리를 가장 효율적으로 실행할 수 있는 경로를 결정하는 DBMS의 구성 요소
사용자의 쿼리를 분석하여 오류 없는지 검사하고 다양한 실행 전략을 평가하여 효율적인 방법을 선택함
힌트 (Hint)
SQL 쿼리를 작성할 때 옵티마이저에게 쿼리 실행 계획에 대한 제안이나 지시를 제공하는 방법
보통 옵티마이저가 최적의 계획으로 처리하지 못할 경우 직접 제공
SELECT /*+ INDEX(e emp_emp_id_idx) */ employee_id, name
FROM employees e
WHERE employee_id = 1234;
시퀀스 (Sequence)
DB에서 자동으로 순차적인 숫자를 생성할 때 사용하는 객체
주로 PK 생성 목적으로 사용
뷰 (View)
하나 이상의 테이블에서 가져온 데이터를 기반으로 하는 가상의 테이블
실제 데이터를 저장하지 않고, 기존 테이블의 데이터를 특정한 형태로 표현한 SQL 쿼리의 결과를 보여줌
- 장점 : 특정 사용자에게 일부 데이터만 보여줄 수 있음
- 단점 : 인덱스 X
트리거(Trigger)
DML 문이 수행될 때 자동으로 실행되는 프로시저
정규화 (Normalization)
데이터를 구조화하여 중복을 최소화하고 데이터 무결성을 증진시키기 위한 과정
정규화의 주요 목적은 이상 현상을 방지하는 것
이상 현상 (Anomalies)
잘못된 DB 구조로 인해 데이터를 삽입, 삭제, 갱신할 때 발생할 수 있는 일련의 문제
- 삽입 이상(Insertion Anomalies): 새 데이터를 넣을 때 원하지 않는 데이터까지 추가해야하는 문제
ex. 동아리 가입 테이블에서 학생ID, 이름, 동아리명이 필드일 경우, 한 학생이 아무 동아리에 가입하지 않았다면 동아리명 입력 없이 데이터를 삽입할 수 없는 문제가 발생 - 삭제 이상(Deletion Anomalies): 데이터 삭제할 때, 관련된 다른 유용한 데이터까지 함께 삭제되어야 하는 문제
ex. 한 학생이 동아리 탈퇴하면 그 학생의 모든 정보가 제거 됨 - 수정 이상(Modification Anomalies): 데이터 중복으로 인 해 한 개 이상의 위치에서 동일한 데이터를 갱신해야할 때 발생하는 문제
ex. 개명한 경우 여러 테이블에 수정해야함
Connection Pool
Connection을 초기에 생성해놓고 관리하는 곳
Connection은 TCP/IP 연결에 의한 3-way handshaking이 발생하여 연결에 오랜 시간이 걸림
N + 1 문제
예시
블로그 포스트와 각 포스트에 달린 댓글을 데이터베이스에서 불러오는 상황
포스트 목록을 조회하고, 각 포스트에 대한 댓글도 조회해야 함
- 첫 번째 쿼리를 통해 포스트 목록을 불러옴
ex. SELECT * FROM posts; 이 쿼리로 10개의 포스트를 불러옴 - 각 포스트에 대해 댓글을 불러오기 위한 추가 쿼리가 실행
ex. SELECT * FROM comments WHERE post_id = ?; 이 쿼리는 각 포스트마다 실행되어 총 10번 실행
결과적으로, 1번의 포스트 조회 쿼리와 10번의 댓글 조회 쿼리, 총 11번의 쿼리가 실행
이것이 N+1 문제이며, N은 첫 번째 쿼리로 불러온 포스트의 수
해결 방법
필요한 모든 데이터를 가능한 한 적은 수의 쿼리로 불러오는 것
- 조인(Joins) 사용: 관련된 테이블을 조인하여 한 번의 쿼리로 필요한 모든 데이터를 가져옴
ex. SELECT * FROM posts LEFT JOIN comments ON posts.id = comments.post_id; - 서브쿼리 사용: 메인 쿼리의 결과를 사용하는 서브쿼리를 작성하여 한 번에 모든 관련 데이터를 가져옴
'💻 개발IT > 기타' 카테고리의 다른 글
| 개인앱 모니터링 알람 옮기기 (0) | 2024.11.09 |
|---|---|
| LLM과 프롬프트 엔지니어링 (0) | 2024.10.28 |
| 홈서버 만들기 with ipTIME, MacBook (0) | 2024.06.25 |
| [면접] Spring 기술 면접 질문 정리 (1) | 2024.05.01 |
| [AdMob] cannot find an ad network adapter with the name(s): GADMAdapterFacebook. (0) | 2024.03.17 |
| [Flutter] java.lang.NoSuchMethodError: No virtual method setRequestAgent(Ljava/lang/String;)Lcom/google/android/gms/ads/AdRequest$Builder; in class Lcom/google/android/gms/ads/AdRequest$Builder; or its super classes (declaration of 'com.google.android.g.. (0) | 2024.03.17 |
| [AdMob] 광고 검사기 소개 및 실행 방법 (0) | 2024.03.16 |
| [AdMob] 전면/리워드 광고 캐싱 적용 후기 (0) | 2024.03.11 |


